在当今微服务架构盛行的时代,一次用户请求往往需要跨越多个服务节点,形成一个复杂的调用链。对于京东这样拥有庞大技术生态的电商平台,如何清晰洞察每一次请求的完整路径、快速定位性能瓶颈与故障根源,是保障系统稳定与用户体验的关键。咚咚作为京东内部核心的即时通讯与协作平台,其服务调用链路同样错综复杂。为此,我们构建了专为咚咚服务的分布式链路追踪数据处理体系。
一、 核心价值:从混沌到清晰的可观测性
分布式链路追踪并非新生概念,但对咚咚而言,其数据处理服务承载着特定而重要的使命:
- 全链路可视化:将一次IM消息的发送、推送、存储、状态同步等跨服务、跨数据中心的调用过程,串联成一幅清晰的时序图谱,使研发与运维人员能够一目了然地看到请求的“全貌”。
- 性能瓶颈诊断:精准度量每个服务模块、甚至每个数据库查询的耗时,快速定位导致延迟的“慢节点”,为性能优化提供数据支撑。
- 故障根因定位:当线上出现异常或错误时,能够根据TraceID迅速关联到相关的错误日志、服务异常和系统指标,极大缩短故障排查的平均恢复时间(MTTR)。
- 依赖分析与容量规划:通过分析服务间的调用关系与流量数据,识别不合理的强依赖或脆弱环节,并为服务的弹性扩缩容提供科学依据。
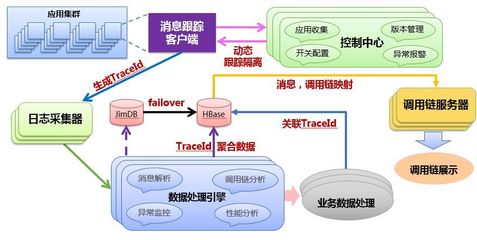
二、 数据处理架构:采集、传输、计算与存储
咚咚的链路追踪数据处理服务是一个典型的高吞吐、低延迟大数据管道,其核心流程可分为四个层次:
1. 数据采集与埋点
在服务代码中通过轻量级Agent或SDK进行无侵入或低侵入式埋点,收集包括TraceID、SpanID、父SpanID、服务名、方法名、时间戳、耗时、标签(Tags)与日志(Logs)等关键元数据。我们特别注重采集的效率和性能损耗,确保对业务服务的影响降至最低。
2. 数据聚合与传输
各服务节点产生的追踪数据(Span)并非立即上报中心。本地Agent会进行初步的缓冲与批量聚合,然后通过高效的异步方式,经由消息队列(如Kafka)进行传输。这一设计有效削峰填谷,避免了海量数据瞬间冲击下游处理系统,并提供了良好的解耦与可靠性保障。
3. 流式处理与计算
这是数据处理服务的“大脑”。我们采用流式计算框架(如Flink)对持续涌入的链路数据进行实时清洗、关联与聚合。
- 清洗:过滤掉调试数据、无效数据,规范数据格式。
- 关联:将属于同一个Trace的所有Span,根据TraceID和SpanID关系重新组织成完整的调用树。这是将原始数据转化为有用信息的关键一步。
- 聚合:实时计算关键指标,如服务每秒请求量(QPS)、平均响应时间(AvgRT)、错误率等,并生成服务于监控告警的时序数据。
4. 数据存储与索引
处理后的数据需要存入合适的存储引擎,以支持灵活的查询:
- 明细数据存储:将完整的链路调用树存入如Elasticsearch等搜索引擎,支持根据TraceID、服务名、接口名、耗时范围、错误码等多维度组合查询,便于问题排查。考虑到数据量巨大,我们会制定合理的分片与滚动过期策略。
- 聚合数据存储:将实时计算出的服务级、接口级指标存入时序数据库(如InfluxDB或TDengine),用于绘制监控大盘和进行趋势分析。
三、 面临的挑战与应对策略
在服务京东海量用户的咚咚平台上构建该体系,我们面临并克服了诸多挑战:
- 数据洪峰:大促期间,消息流量激增,链路数据量可能呈指数级增长。我们通过动态采样策略(如固定比例采样、低频服务全采样、错误请求全采样)来控制数据总量,在保证可观测性的同时平衡存储与计算成本。
- 处理延迟与数据一致性:要求近实时的链路查询体验。我们优化流处理作业的吞吐与延迟,并确保Span跨节点时钟同步,使重组后的调用时序准确无误。
- 多语言与复杂技术栈:咚咚后端涉及Java、Go、C++等多种语言。我们提供了统一的数据协议标准和不同语言的客户端库,确保数据模型的统一。
- 成本控制:海量数据的存储与计算成本高昂。我们通过数据分层(热数据与冷数据)、压缩算法、合理的TTL策略以及使用高性价比的存储方案来进行精细化成本管理。
四、 最佳实践与未来展望
在实践中,我们将链路数据与日志、指标数据深度融合,构建了统一的“可观测性”平台。当告警触发时,工程师可以一键从指标下钻到关联的异常链路,再从链路查看具体的错误日志,形成了高效排查的闭环。
咚咚的分布式链路追踪数据处理服务将继续演进:向智能化方向发展,如基于历史链路模式自动识别异常调用、预测潜在故障;提升分析深度,将业务标签(如用户ID、消息类型)与链路数据结合,实现从技术视角到业务视角的追踪分析;并进一步优化性能与成本,探索更高效的编码、压缩与存储方案。
一个稳定、高效、智能的链路追踪数据处理服务,如同为咚咚这艘巨型舰船装上了精密的“航行记录仪”和“故障诊断系统”,它不仅是技术保障的基石,更是驱动系统持续优化与业务稳健前行的重要引擎。